5 Expression génétique
Rappels :
L’ADN est le support de l’information génétique. Il est constitué de deux brins antiparallèles qui sont des polymères de nucléotides. Un nucléotide possède une même structure de base : un désoxyribose, un groupement phosphate et une base. Il existe quatre sortes de base (Adénine, Thymine, Cytosine et Guanine) et donc quatre sortes de nucléotides. C’est l’enchaînement des nucléotides et donc des bases, qui code l’information. Une portion de chromosome, donc une portion d’ADN, qui code pour une information s’appelle un « gène ».
A retenir :
Quand l’ordre des bases d’un gène est modifié, le caractère découlant de cette information est également modifié. Ainsi, si la mutation touche une protéine dont le rôle est essentiel dans le métabolisme, l’individu pourra présenter une maladie dite « génétique ». C’est le cas par exemple de la mucoviscidose. Chez les individus atteints de mucoviscidose, on note la présence de deux allèles mutés responsables de l’expression d’une protéine non fonctionnelle impliquée dans l’excrétion des ions chlore à l’origine d’une fluidification du mucus des voies respiratoires et digestives qui devient alors épais et encombrant. Cette protéine a perdu un constituant de base appelé la « phénylalanine » en position 508.
C’est ce simple changement qui est responsable du dysfonctionnement de la protéine et donc du changement dans le fonctionnement de l’organisme. L’information portée par l’ADN est donc traduite en protéines responsables du phénotype d’un individu. De manière générale comme l’ADN code pour des protéines responsables de nos caractères, on dit que le « génotype », c’est-à-dire l’ensemble des gènes que possède un individu, contrôle le « phénotype », c’est-à-dire l’ensemble des caractères que possède cet individu.
Du génome à la protéine :
Genome-fr.svg, domaine public, via Wikimédia Commons, modifié par Sandra Rivière https://upload.wikimedia.org/wikipedia/commons/3/38/Genome-fr.svg?uselang=fr
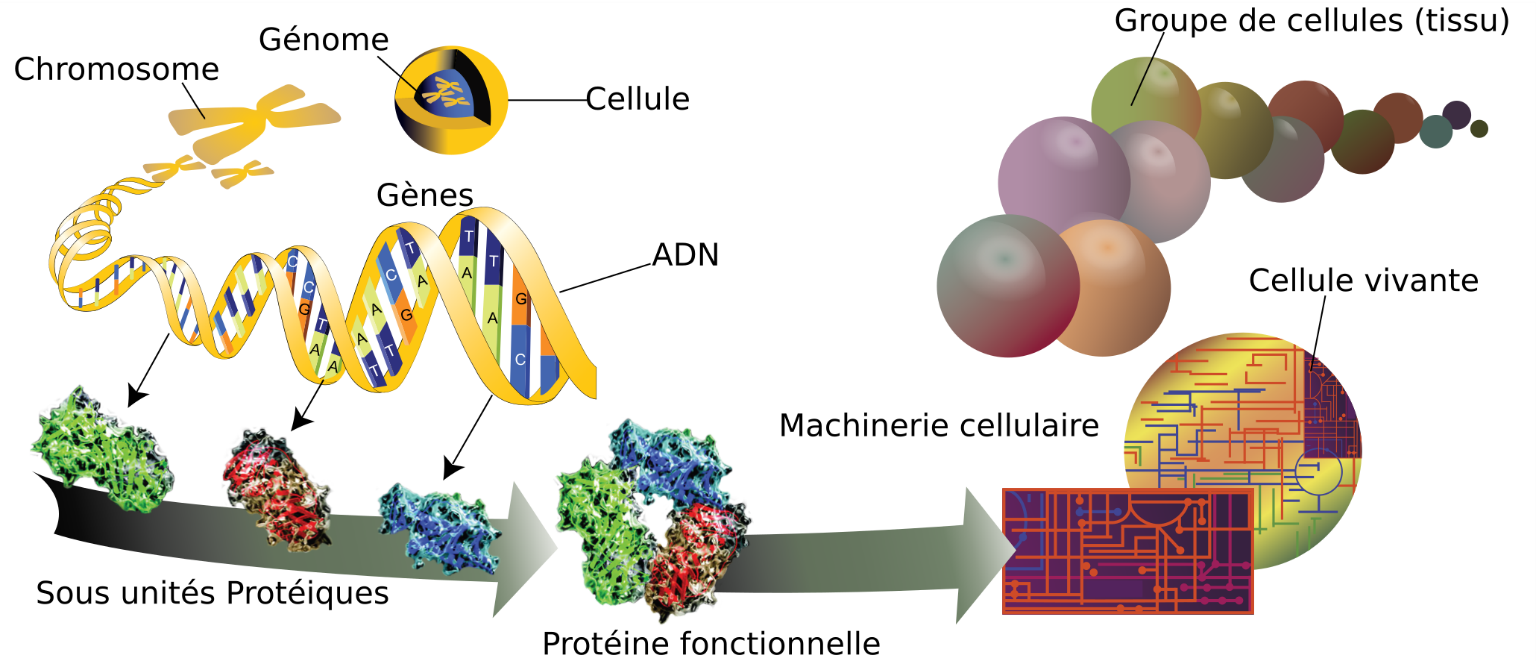
Les protéines sont donc des macromolécules constituées d’unités appelées « acides aminées ». Il en existe 20 chez les mammifères. Chaque protéine a une fonction précise. On trouve plusieurs sortes de protéines :
- Protéines de structure (exemple : le collagène)
- Protéines de transport (exemple : les canaux ioniques)
- Protéines régulatrices (exemple : les récepteurs hormonaux)
- Protéines de signalisation (exemple : les marqueurs du soi)
- Protéines motrices (exemple : l’actine et la myosine des muscles)
- Protéines catalytiques (exemple : les enzymes)
L’ADN est localisé dans le noyau alors que les protéines sont fabriquées dans le cytoplasme. On pourrait supposer que l’ADN sorte du noyau en passant par les pores nucléaires, de diamètre 45 nm, pour être lu et traduit en protéines dans le cytoplasme. Cependant il n’en est rien. En effet, l’ADN n’est pas toujours entièrement décondensé : la double hélice d’ADN s’enroule autour de protéines appelées histones formant alors un filament appelé « chromatine » dont le diamètre est de 10 nm. Cette chromatine, même si elle possède un diamètre inférieur à celui des pores nucléaires, ne peut en sortir en raison du fait qu’elle est très longue, non rectiligne et surtout qu’elle est enchevêtrée avec les autres chromatines (rappel : l’Homme possède 46 chromosomes soit 46 filaments de chromatine). Ainsi la cellule conserve l’ADN dans son noyau mais envoie dans le cytoplasme un messager de nature polynucléotidique. Ce messager peut être mis en évidence par l’expérience suivante : des cellules sont mises en culture sur un milieu contenant des bases radioactives. Au bout de 15 minutes la radioactivité est détectée dans le noyau de ces cellules. Les chaînes polynucléotidiques ont donc été produites. Les cellules sont transférées sur un milieu ne contenant plus de bases radioactives. Au bout de quelques minutes, la radioactivité est observée dans le cytoplasme. On en déduit que des chaînes polynucléotidiques produites sont sorties du noyau. Leur étude montre qu’elles sont de courte taille et beaucoup plus fines que des molécules d’ADN. On les appelle des ARN messagers ou ARNm. Ce sont des acides ribonucléiques dont la structure est légèrement différente de celle de l’ADN :
- ils ne présentent qu’un simple brin polynucléotidique lui permettant un passage plus facile par les pores nucléaires,
- les nucléotides ne sont pas constitués d’un désoxyribose mais d’un ribose
- ils ne contiennent pas de Thymine mais une autre base pyrimidique : l’Uracile compatible avec l’Adénine.
Comparaison ADN/ARN
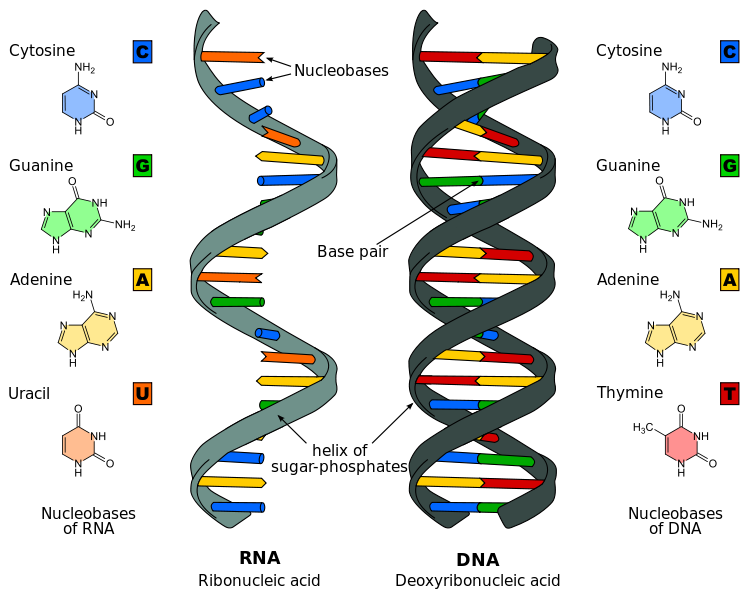
Difference DNA RNA-EN.svg par Fichier: Difference DNA RNA-DE.svg : Sponk CC-BY-SA-3.0 via Wikimédia Commons, https://commons.wikimedia.org/wiki/File:Difference_DNA_RNA-EN.svg?uselang=fr
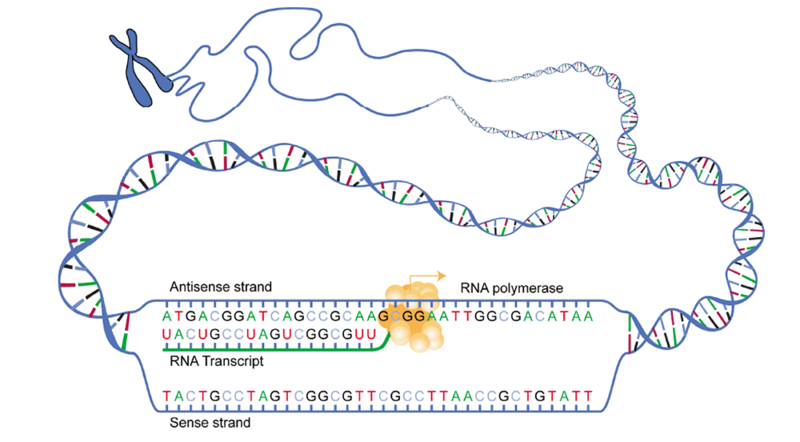
L’étape qui consiste à copier le code d’un gène sous forme d’ARNm est appelée la transcription. Elle se déroule en trois étapes :
- l’INITIATION : fixations de l’ARN polymérase sur le brin à transcrire et ouverture de la double hélice par rupture des liaisons faibles
- l’ELONGATION : assemblages par l’ARN polymérase des nucléotides complémentaires à ceux du brin transcrit. C’est lors de cette étape qu’en face d’une Adénine, au lieu de positionner une Thymine, l’ARN polymérase positionne un Uracile.
- la TERMINAISON : décrochage de l’ARN polymérase à la fin du gène et libération de l’ARN non mature appelée ARN prémessager.
Les étapes de la transcription :
Transcription.jpg, par Calibuon chez English Wikibooks, Domaine public, https://en.wikipedia.org/wiki/File:Transcription.jpg

Détails de l’élongation de l’ARN
ADN transcription.png, via Wikimedia commons, Domaine public, https://commons.wikimedia.org/wiki/File:DNA_transcription.png
Chez les eucaryotes ( organismes dont la ou les cellules ont un noyau) , il y a plusieurs ARN polymérases qui se fixent les unes à la suite des autres sur un même gène à transcrire. De ce fait il y a plusieurs ARN qui sont fabriqués en même temps mais qui présentent une taille d’élongation différente dépendante du stade d’avancement de l’ARN polymérase sur le gène. La transcription de plusieurs molécules d’ARN simultanément se repère très bien au microscope électronique car l’ensemble prend une forme de plume.
Transcription de plusieurs molécules d’ARN simultanément

Source : http://bret-svt.e-monsite.com/pages/1ere-s/theme-1-ii.html
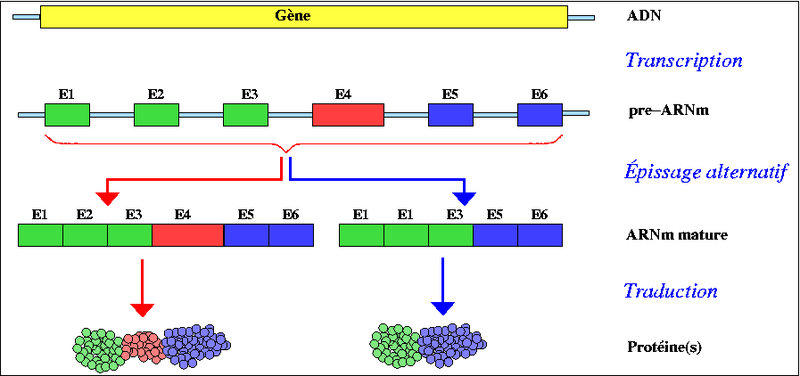
L’ARN correspondant à un gène est de courte taille et ne possède qu’une partie de la séquence d’ADN dont il est issu : en effet l’hybridation des deux molécules montre de nombreuses portions d’ADN ne trouvent pas d’équivalent dans l’ARNm. L’ARN pré-messager est constitué de séquences codantes qui sont conservées et appelées « exons », et des séquences non codantes qui ne seront pas conservées et qui sont appelées « introns ». Ainsi l’ARN messager va être produit en deux temps :
- transcription de l’ADN en ARN pré-messager
- maturation de l’ARN pré-messager en ARN messager par épissage (excision des introns)
L’épissage peut être alternatif : à partir d’un même transcrit l’ARN pré-messager peut subir différents épissages (élimination des introns et parfois de quelques exons) permettant d’obtenir plusieurs ARN messagers différents et donc plusieurs protéines différentes.
La maturation de l’ARN pré-messager par épissage :
Altspli.png, Original téléversé par Benny sur Wikipédia français, CC-BY-SA-3.0-migrated, https://commons.wikimedia.org/wiki/File:Altspli.png?uselang=fr
Le code génétique, c’est-à-dire l’enchaînement des bases de l’ADN, est conservé dans l’ARN messager. Le système de correspondance entre l’ARN messager et les acides aminés est basé sur des combinaisons de trois nucléotides appelés « codons ». Il existe au total 64 combinaisons possibles et donc 64 codons.
Un codon correspond à un acide aminé parmi lesquels la méthionine qui correspond au codon d’initiation de la protéine. Il existe également trois codons STOP permettant l’arrêt de la traduction de l’ARN messager en protéines. Il y a ainsi 61 combinaisons qui correspondent aux 20 acides aminés. Ainsi plusieurs codons codent pour le même acide aminé, on dit que le code génétique présente une « redondance». Les expériences de transgénèse entre animaux voir même entre êtres vivants de règnes différents (animaux, végétaux, etc….) prouvent que le code génétique est universel.
Le code génétique :
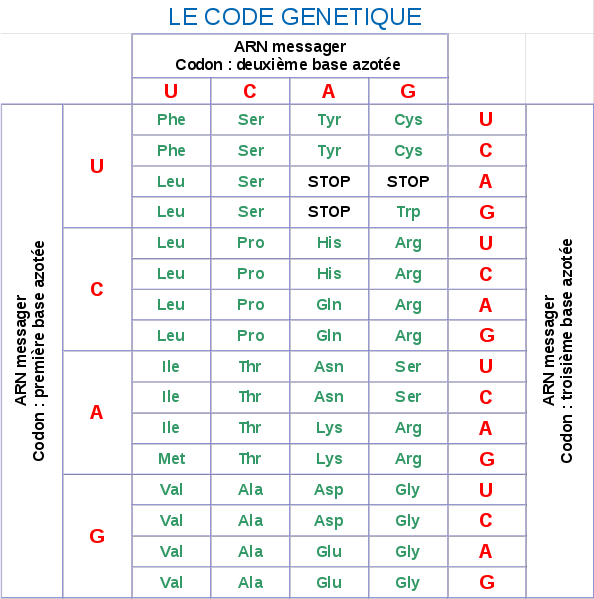
Phe : phénylalanine
Ser : Sérine
Tyr : Tyrosine
Cys : Cystéine
Leu : Leucine
Trp : Tryptophane
Pro : Proline
His : Histidine
Arg : Arginine
Gln : Glutamine
Ile : Isoleucine
Thr : Thréonine
Asn : Asparagine
Lys : Lysine
Asp : Acide asparagique
Met : Méthionine
Val : Valine
Ala : Alanine
Gly : Glycine
Glu : acide glutamique
Thr thréonine
SVT CodeGenetique.svg, par Quo-Fata FERUNT, via Wikimédia Commons, https://commons.wikimedia.org/wiki/File:SVT_CodeGenetique.svg
Les éléments impliqués dans la synthèse des protéines sont :
- les ribosomes qui traduisent les codons,
- l’ARNm qui transmet l’information génétique du noyau au cytoplasme,
- les acides aminés qui constituent la protéine,
La synthèse des protéines ou traduction se fait en donc en trois étapes :
1. l’INITIATION : Elle débute toujours au niveau d’un codon AUG, appelé codon initiateur, au niveau duquel un ribosome s’assemble sur l’ARNm. Ce codon correspond à une méthionine. Ainsi chaque protéine sera toujours initiée par une méthionine qui sera par la suite éliminée.
2. l’ELONGATION : Le ribosome se déplace sur l’ARNm, lisant les codons les uns à la suite des autres et accrochant ainsi les acides aminés correspondants les uns à la suite des autres et ce, grâce à des liaisons peptidiques.
3. TERMINAISON : Le ribosome arrive au niveau d’un codon STOP, ce qui déclenche la dissociation du complexe ARNm – ribosome, et la libération des sous-unités du ribosome, de l’ARNm et de la chaîne d’acides aminés appelée « polypeptide » (avec élimination de la méthionine) dans le cytoplasme : la synthèse s’achève.
Une fois libérée, la chaîne polypeptidique va prendre sa conformation spatiale et entrera en fonction. En cas de mauvaise ou de non transcription d’un gène, les protéines correspondantes et nécessaires au fonctionnement de l’organisme seront soit absentes soit on fonctionnelles, modifiant ainsi le phénotype de l’individu.
Les étapes de la traduction
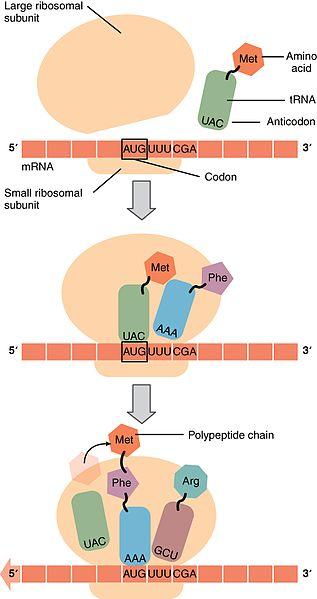
0327Translation.jpg par OpenStax via Wikimédia Commons, CC-BY-4.0, https://commons.wikimedia.org/wiki/File:0327_Translation.jpg
Le phénotype s’exprime à trois grandes échelles : de l’organisme (macroscopique), cellulaire (microscopique) et moléculaire.
Dans l’exemple de la drépanocytose, une mutation, substitution du 20ème nucléotide de la chaîne béta de l’hémoglobine (A est remplacé par T) entraîne la présence d’une valine comportant un radical hydrophobe dans la chaîne béta de l’Hémoglobine S (hémoglobine drépanocytaire). Cela entraîne la polymérisation des molécules d’HbS qui forment alors des fibres insolubles. Ainsi la modification de la séquence en acides aminés a modifié la structure de la protéine. La modification du génotype a ainsi entraîné une modification du phénotype moléculaire. De plus les fibres rendent les hématies indéformables et fragiles : le phénotype moléculaire a modifié le phénotype cellulaire. Les hématies en forme de faucille vont se bloquer dans les capillaires sanguins, entraînant de fortes crises douloureuses et subir une destruction rapide à l’origine d’une anémie importante : le phénotype cellulaire a modifié le phénotype macroscopique.
L’expression du génotype dépend donc de facteurs internes et notamment de la séquence régulatrice située en amont des gènes sur la molécule d’ADN. Cette séquence possède un promoteur permettant de fixer soit un facteur de transcription à l’origine de la fixation de l’ARN polymérase, soit un répresseur empêchant la fixation de cette dernière. Facteurs de transcription et répresseurs sont des protéines produites à partir des gènes de développement.
L’expression du génotype dépend également de facteurs externes. L’hémoglobine HbS devient insoluble et fibreuse dans des conditions de déshydratation ou de manque de dioxygène seulement. Ainsi si on évite ces situations, l’hémoglobine HbS se comporte normalement. Après leur formation, les protéines sont donc soumises à l’action des facteurs environnementaux susceptibles de modifier leurs caractéristiques et donc le phénotype moléculaire, cellulaire et macroscopique.
SCHEMA BILAN

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
http://svt.ac-dijon.fr/schemassvt/IMG/expressgeneV2.gif
VOCABULAIRE
Information génétique: ensemble des informations qui spécifient les caractéristiques héréditaires de chaque cellule.
ADN: Acide désoxyribonucléique, molécule universelle, contenant un message déterminé par la séquence de nucléotides.
Protéine: Macromolécule dont la structure est déterminée par la succession des acides aminés.
Acide aminé: Unité de base des protéines. Il en existe 20 différents. Le nombre et l’ordre de ces AA reliés par des liaisons peptidiques varient d’une protéine à l’autre, ce qui est à l’origine d’une importante diversité des protéines.
Gène: Segment d’ADN constituant une unité d’information génétique, à l’origine d’un caractère.
Allèles: Séquences de nucléotides correspondant aux différentes versions d’un gène.
Phénotype: Ensemble des traits observables (caractères anatomiques, morphologiques, moléculaires, physiologiques) caractérisant un être vivant donné.
Génotype: Ensemble des allèles d'un individu.
Codon: Combinaison (triplet) de trois nucléotides de l’ARNm correspondant à un acide aminé de la protéine.
Codon d’initiation: AUG, codon de début de conversion de l’ARNm en chaîne d’acides aminés.
Codon stop: codon qui ne correspond à aucun acide aminé et arrête la conversion de l’ARNm en chaîne d’acides aminés.
Redondance du code génétique: plusieurs codons codent pour le même acide aminé dans le code génétique.
Expression du patrimoine génétique -SVT - LA VIE 1ère spé #5 - Mathrix
Date de dernière mise à jour : 22/05/2021